|
I am a Member of Technical Staff at OpenAI, building the next generation of the reasoning models. I received a PhD in Computer Science from Mila, University of Montreal advised by Pierre-Luc Bacon and Aaron Courville. My PhD was focused on parameter, compute, and data efficiency in reinforcement learning. During my PhD, I interned with David Silver's RL team at DeepMind. Before that, I studied at Cornell University, Higher School of Economics, and Lomonosov Moscow State University. Email / CV / Google Scholar / Twitter / GitHub |
|
|
|
|
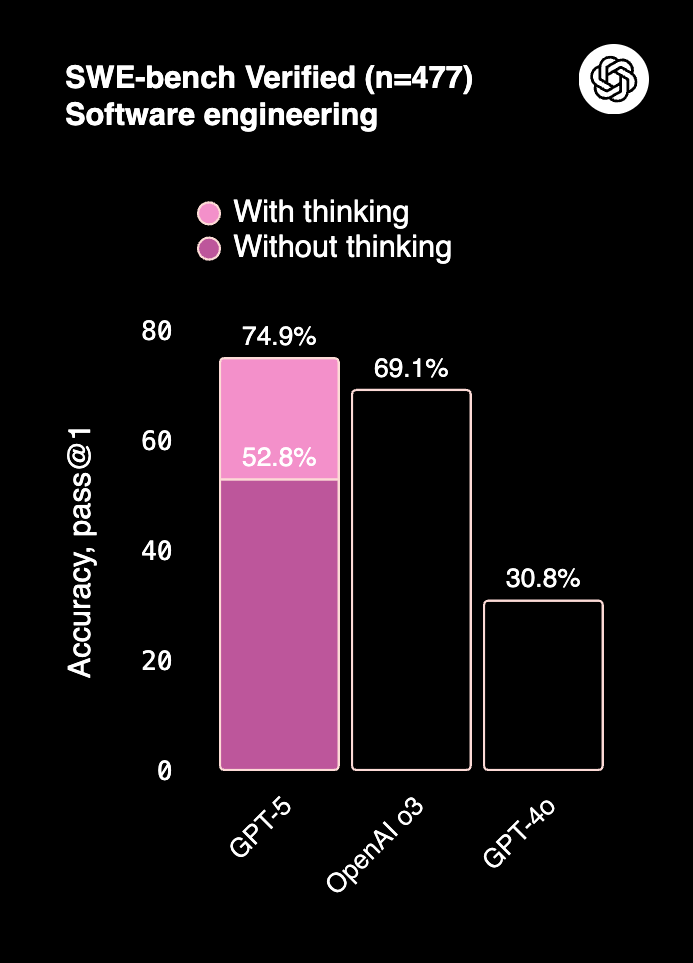
2025 [Blogpost] |
|
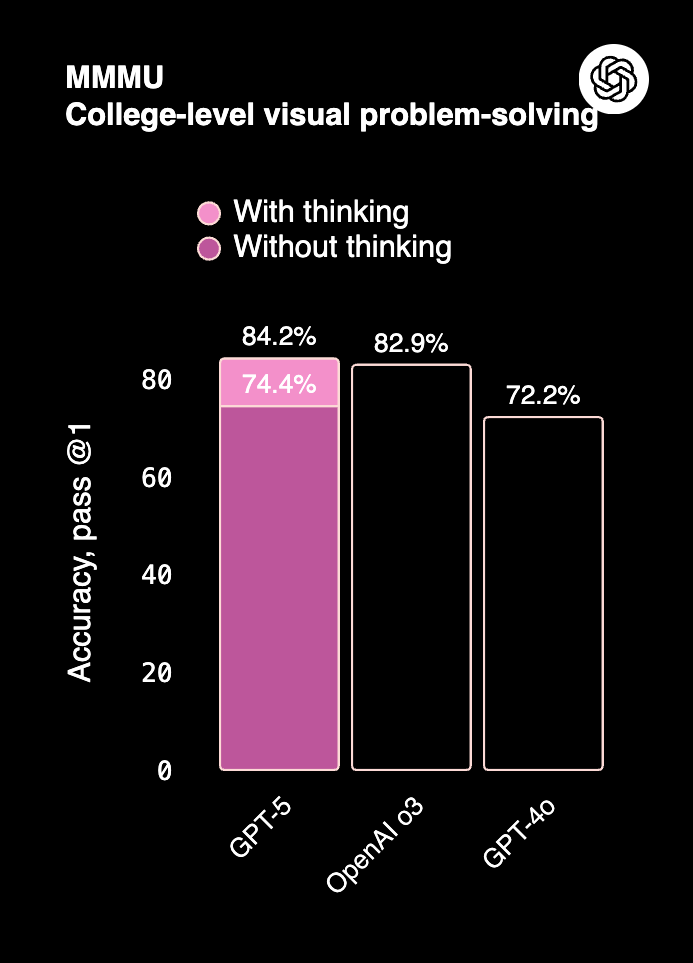
2025 [Blogpost] |
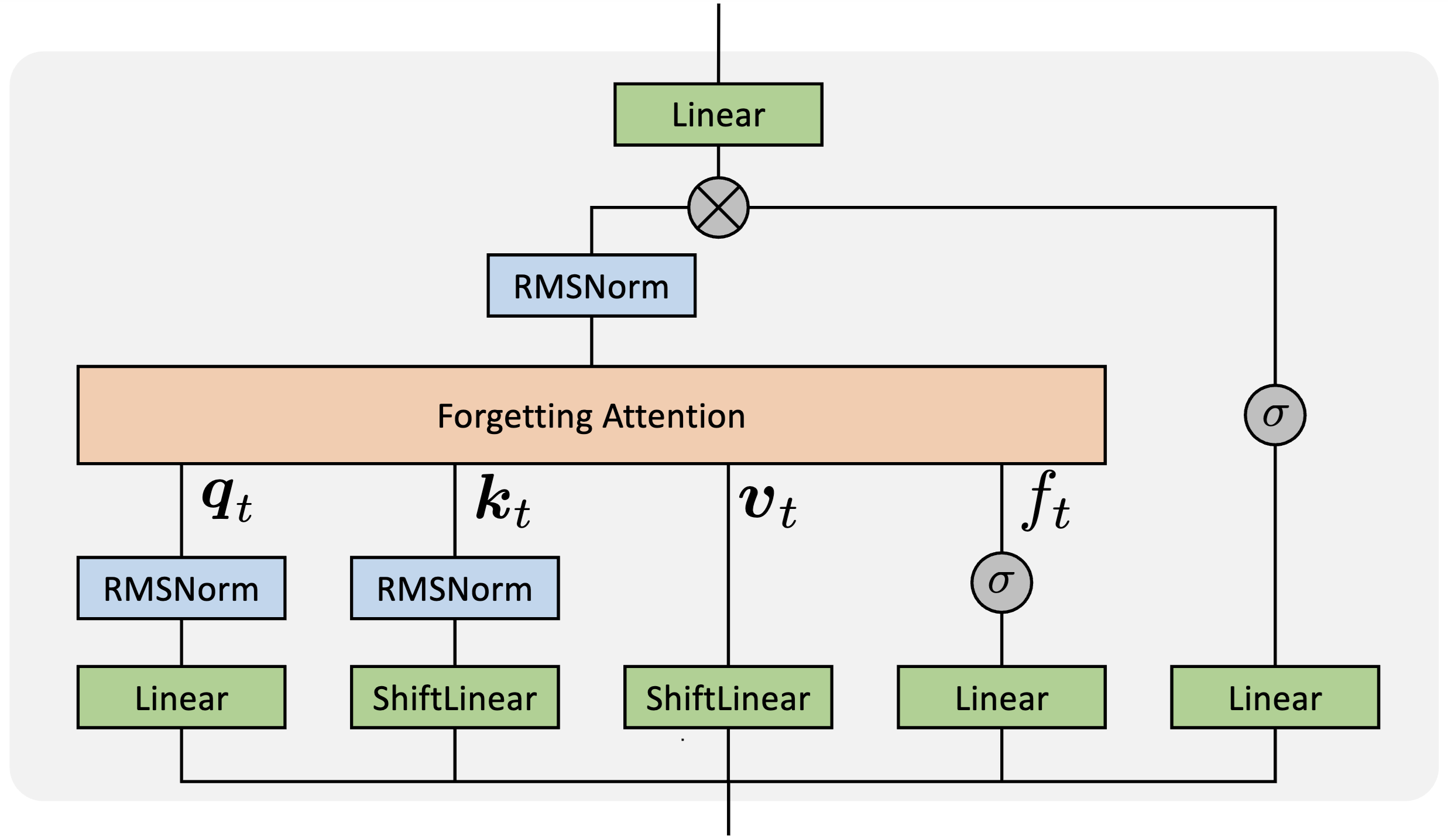
|
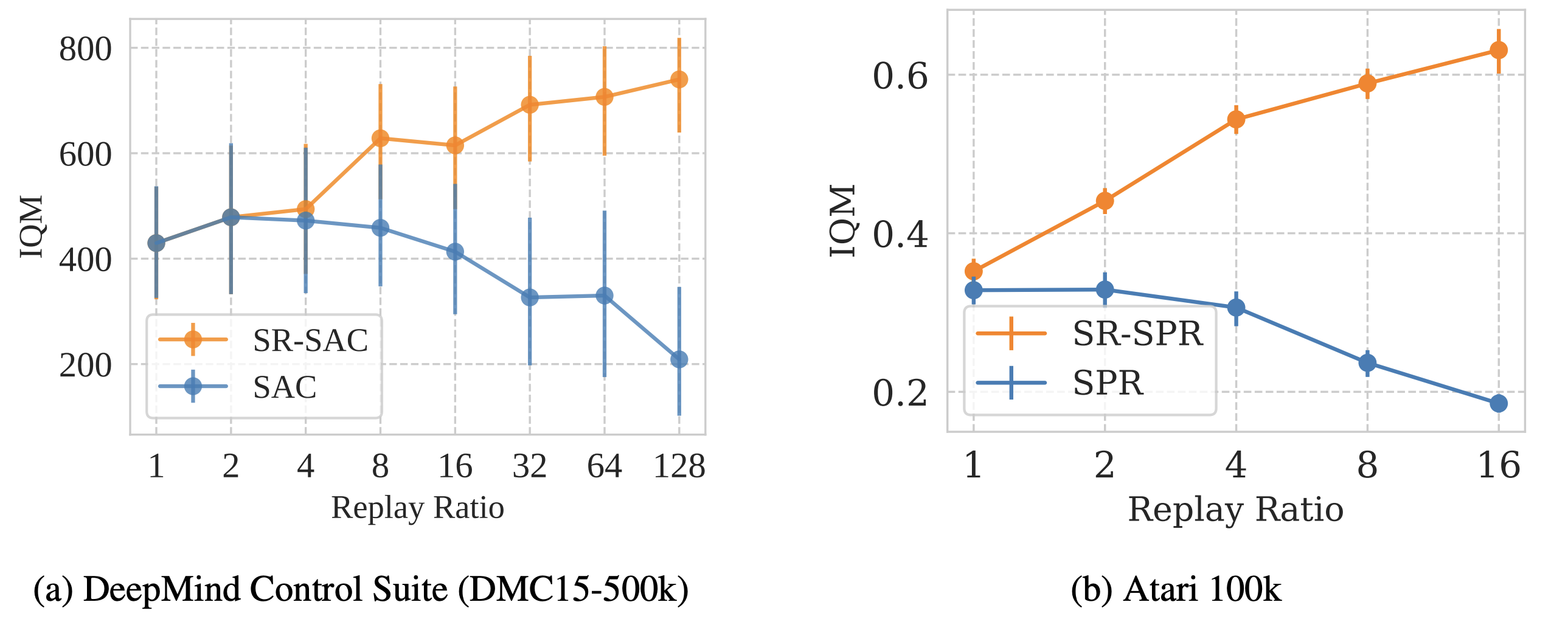
Zhixuan Lin, Evgenii Nikishin, Owen He, Aaron Courville ICLR 2025 [PDF] Recurrent sequence models are great at length extrapolation but struggle with retrieval tasks, Transformers have retrieval capabilities but are not naturally generalizing beyond the training context length. We find a simple way to get the best of both worlds. |
|
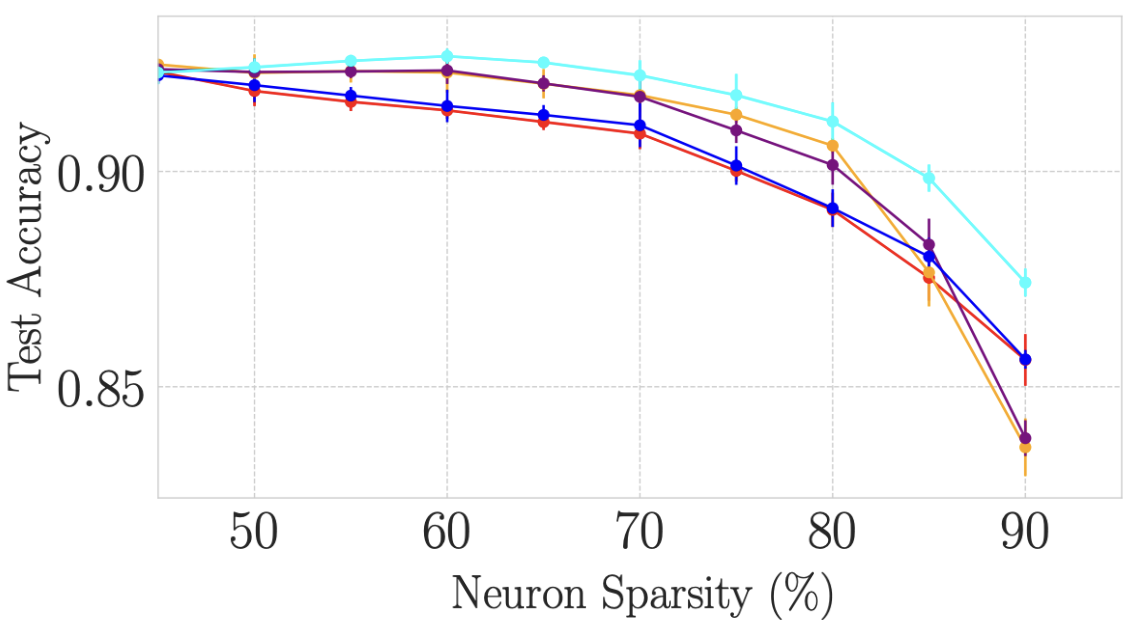
Simon Dufort-Labbé, Pierluca D’Oro, Evgenii Nikishin, Razvan Pascanu, Pierre-Luc Bacon, Aristide Baratin TMLR [PDF] We show that neuron saturation, which traditionally was viewed as undesirable, could instead lead to sparse yet accurate networks. |
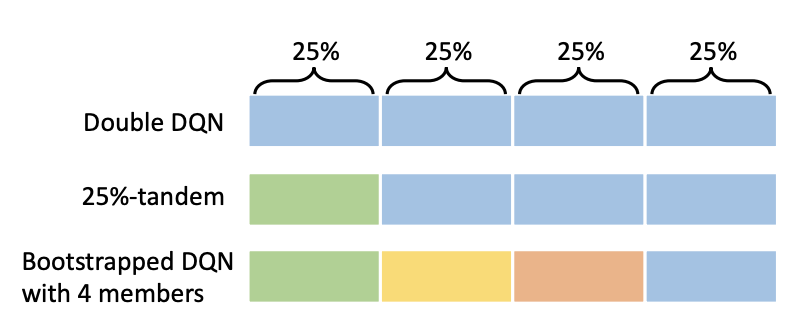
|
Zhixuan Lin, Pierluca D'Oro, Evgenii Nikishin, Aaron Courville ICLR 2024 [PDF, Poster] We demonstrate that individual ensemble members in RL exhibit surprisingly low performance (whilst aggregate returns are adequate) and propose a remedy. |
|
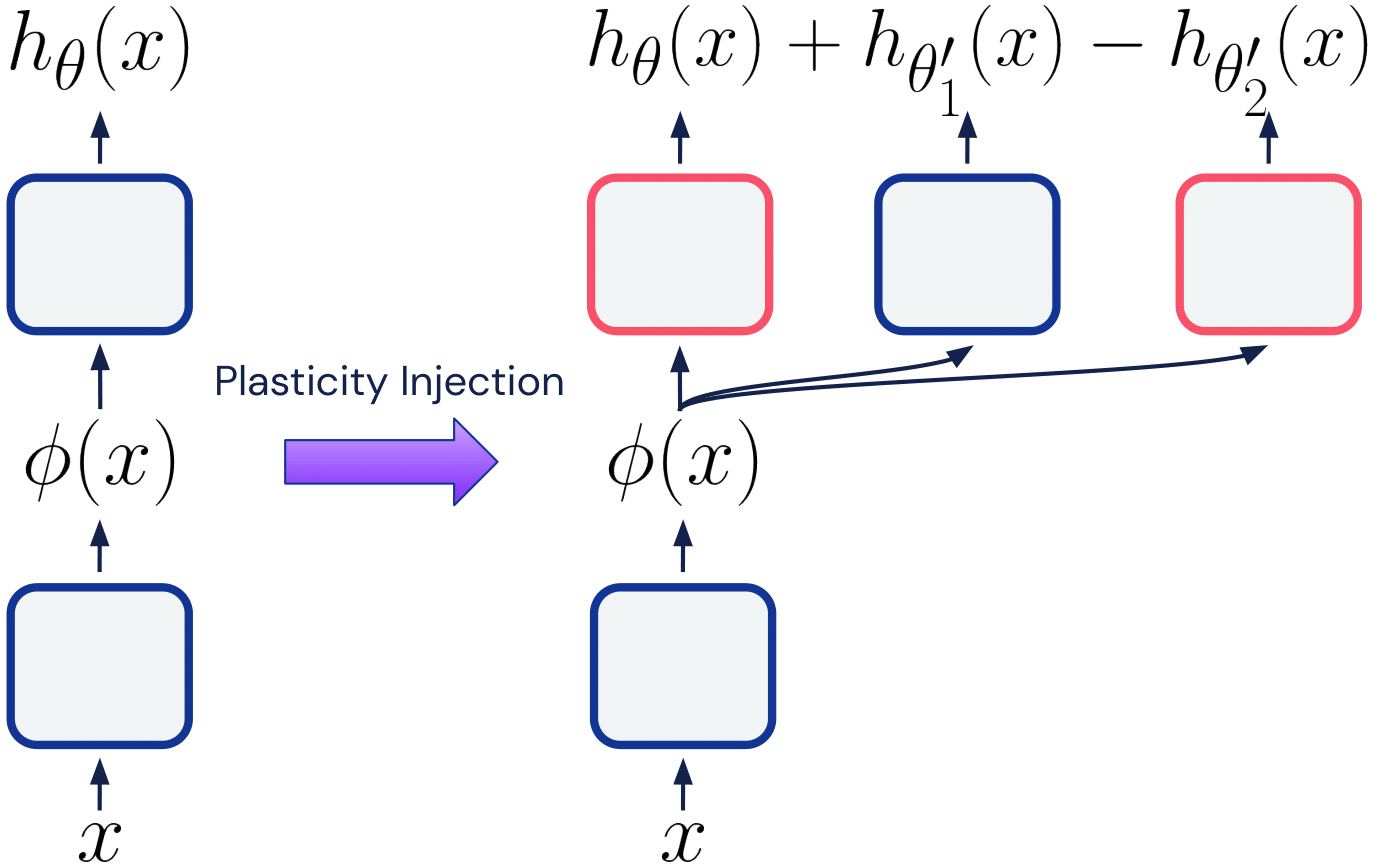
Evgenii Nikishin, Junhyuk Oh, Georg Ostrovski, Clare Lyle, Razvan Pascanu, Will Dabney, André Barreto NeurIPS 2023 (Spotlight); also ICLR 2023 Workshop Track (Spotlight) [PDF, Poster] We propose an intervention for diagnosing the loss of plasticity phenomenon in RL and dynamically growing neural networks in RL for increasing computational efficiency. |
|
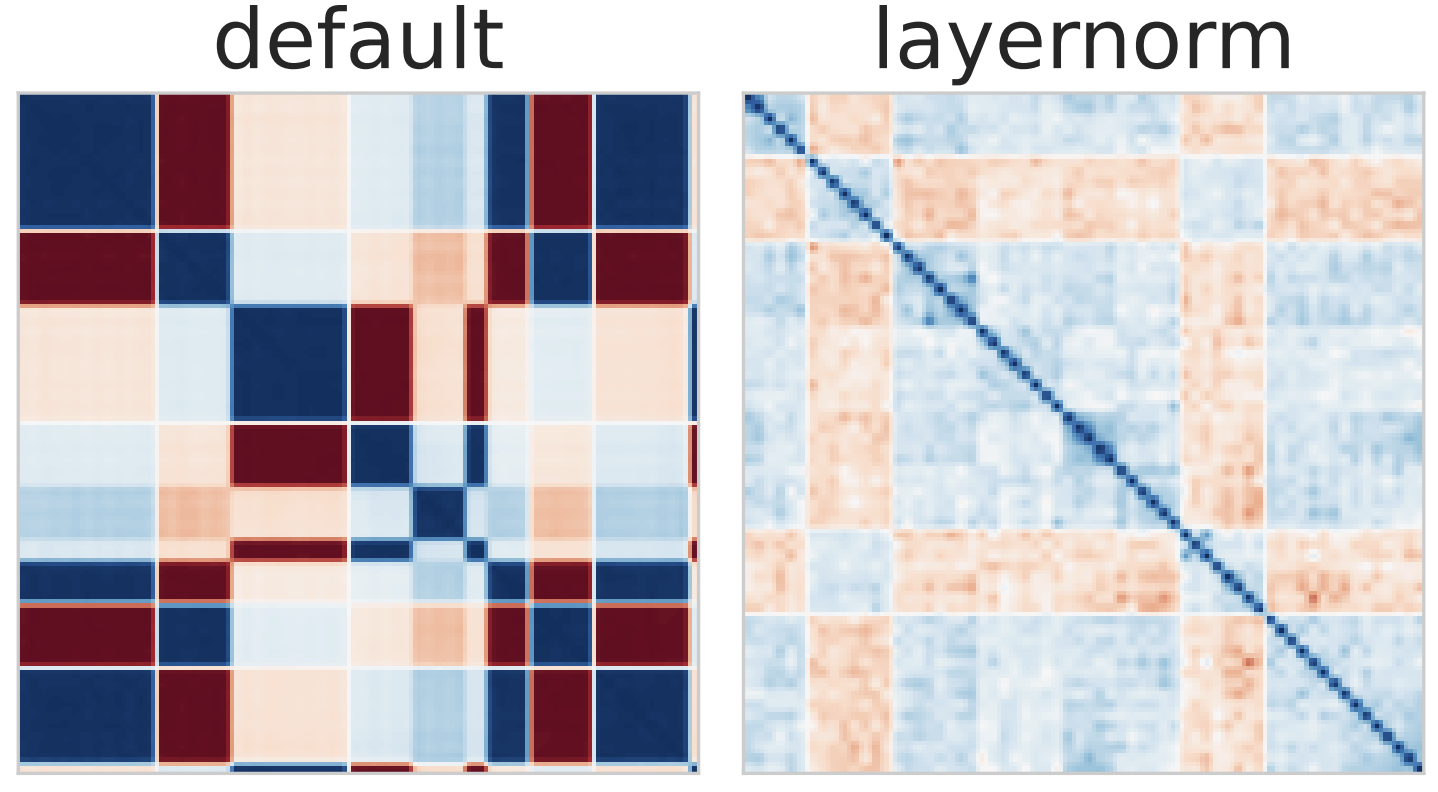
Clare Lyle, Zeyu Zheng, Evgenii Nikishin, Bernardo Ávila Pires, Razvan Pascanu, Will Dabney ICML 2023 (Oral) [PDF] An analysis of plasticity loss showing its relation to pathological loss landscapes and demonstrating efficiency of layer normalization to mitigate it. |
|
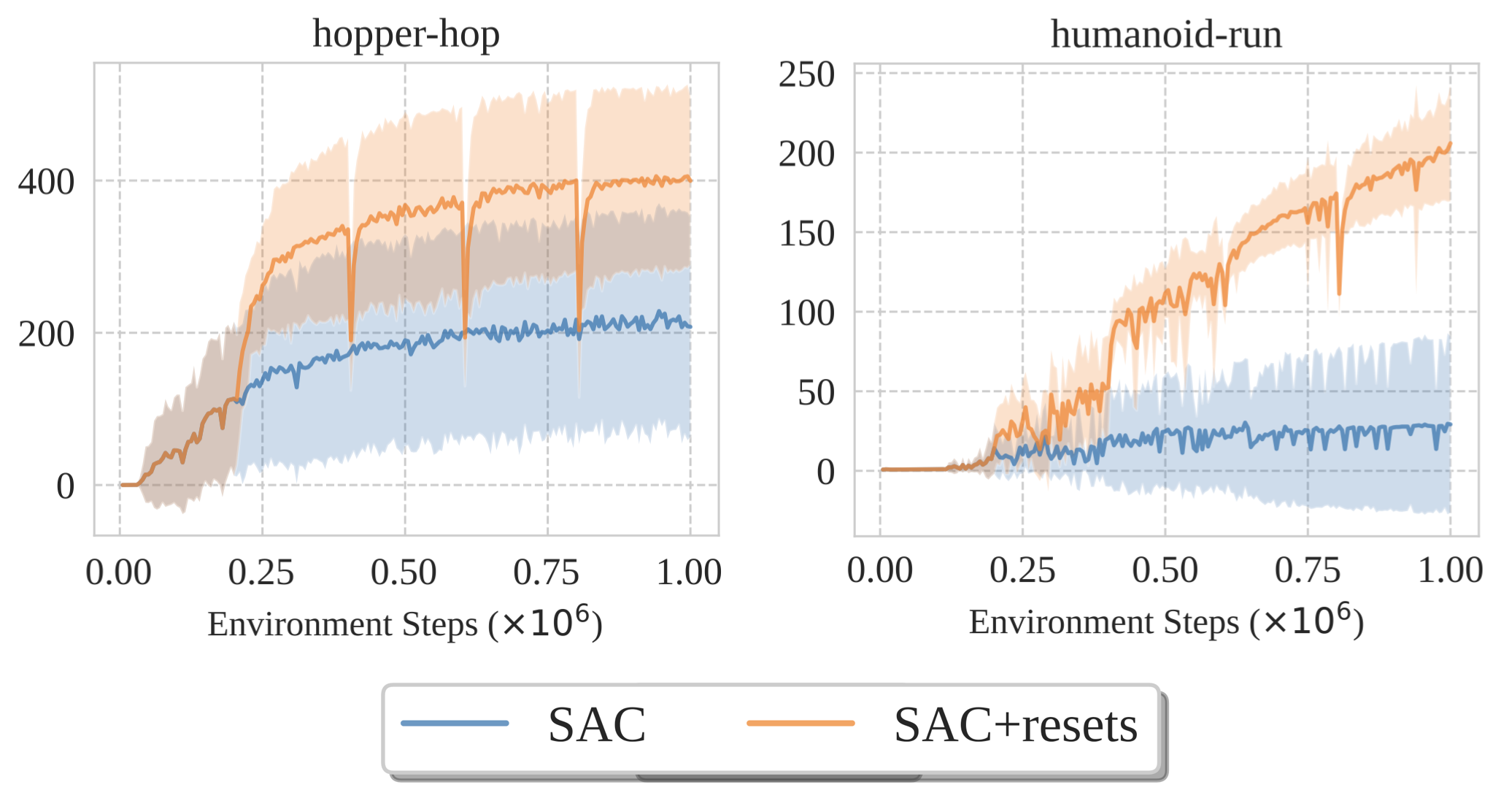
Pierluca D'Oro*, Max Schwarzer*, Evgenii Nikishin, Pierre-Luc Bacon, Marc G. Bellemare, Aaron Courville ICLR 2023 (Oral); also NeurIPS 2022 Workshop Track [PDF, Poster, Code] Resets unlock increasing sample efficiency by scaling the number of updates per environment step. |
|
Evgenii Nikishin*, Max Schwarzer*, Pierluca D'Oro*, Pierre-Luc Bacon, Aaron Courville ICML 2022; also RLDM 2022 [PDF, Short RLDM version, Code, Poster, Blog] We identify a damaging tendency of deep RL agents to overfit early experiences and propose a simple yet powerful remedy based on periodic resetting of a part of the agent. |

|
Evgenii Nikishin, Romina Abachi, Rishabh Agarwal, Pierre-Luc Bacon AAAI 2022; also ICML 2021 Workshop Track [PDF, Code, Poster] A model learning method for RL that directly optimizes the sum of rewards instead of likelihood, a proxy to the agent's objective. |
|
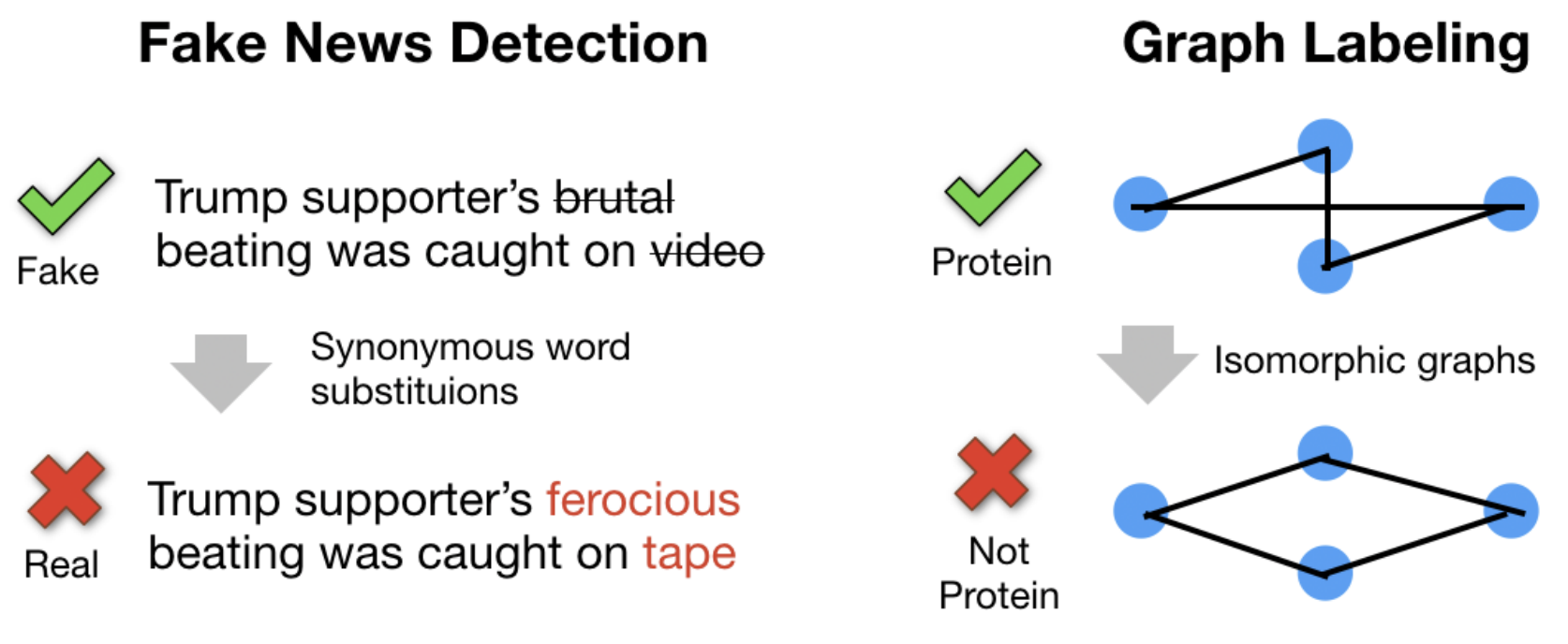
Volodymyr Kuleshov, Evgenii Nikishin, Shantanu Thakoor, Tingfung Lau, Stefano Ermon ArXiv [PDF] We propose an algorithm to construct discrete token adversarial examples based on the notion of synonyms. |
|
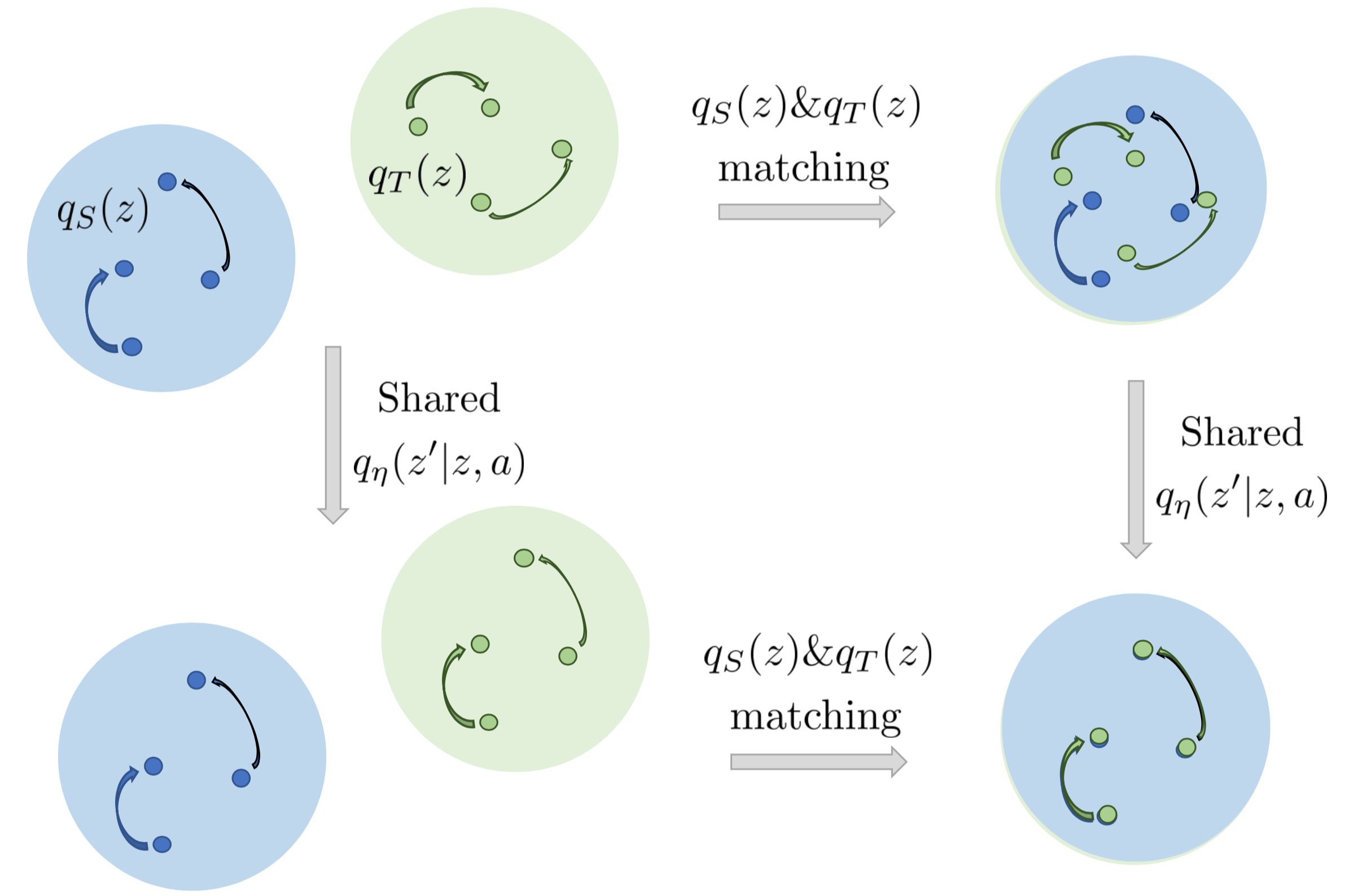
Evgenii Nikishin, Arsenii Ashukha, Dmitry Vetrov NeurIPS 2019 Workshop Track [PDF, Code, Poster] Domain adaptation via learning shared dynamics in a latent space with adversarial matching of latent states. |
|
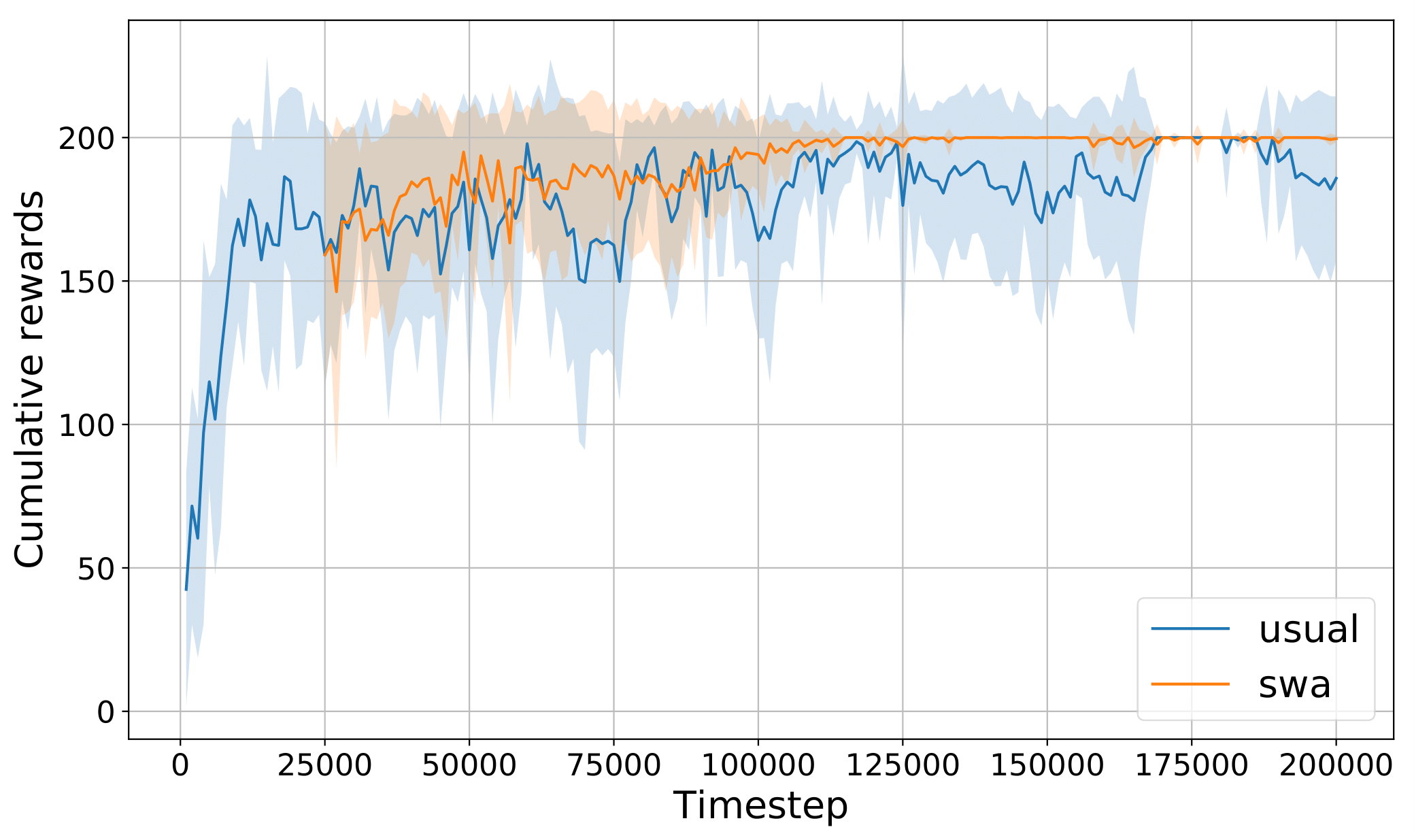
Evgenii Nikishin, Pavel Izmailov, Ben Athiwaratkun, Dmitrii Podoprikhin, Timur Garipov, Pavel Shvechikov, Dmitry Vetrov, Andrew Gordon Wilson UAI 2018 Workshop Track [PDF, Poster] Averaging weights during training of an RL agent stabilizes the achieved performance. |
|
Last update: Oct 2025.
Credit for the template to Jon Barron.
|